Publicado el 10 de noviembre de 2024 por Editor
El Consejo de Normas XBRL ha aprobado una actualización de la nota del grupo de trabajo «Diseño de HTML para Inline XBRL». Este documento proporciona información para los creadores de documentos Inline XBRL (o iXBRL) sobre una variedad de temas técnicos, incluidos el rendimiento, las etiquetas de bloque de texto y la compatibilidad entre HTML y XHTML.
La última actualización busca unificar los mecanismos que han sido adoptados por varios sistemas de presentación de informes, incluidos la SEC de EE. UU. y el programa ESEF de Europa, para vincular hechos iXBRL «ocultos» con contenido HTML legible para humanos. Estos mecanismos ayudan a los revisores y consumidores a comprender los informes Inline XBRL con mayor facilidad, pero actualmente se implementan de manera ligeramente diferente en los diferentes sistemas, lo que crea una carga para los proveedores y emisores de software XBRL. Esta actualización propone un enfoque unificado que puede ser adoptado por otros programas de presentación Inline XBRL.
La nota actualizada se puede encontrar en nuestro sitio de especificaciones aquí
1. Descripción general
Este documento proporciona una serie de recomendaciones para la construcción de HTML para su uso en informes Inline XBRL. Estas recomendaciones tienen como objetivo mejorar la compatibilidad y el funcionamiento con el software de visualización Inline XBRL, garantizar la calidad de los datos XBRL extraídos y mejorar el rendimiento.
2. Nombres de clases CSS reservados
El software de visualización de Inline XBRL puede aplicar clases CSS a un informe Inline XBRL generado para permitir el resaltado de hechos y otras funciones. Para evitar colisiones entre las clases CSS utilizadas por el software de visualización y las clases CSS utilizadas para dar estilo al informe Inline XBRL, los nombres de clase que comiencen con -ixv- deben considerarse reservados para el uso del software de visualización de Inline XBRL y no deben usarse en un informe Inline XBRL ni en ninguna hoja de estilo que lo acompañe.
Si el software de visualización Inline XBRL necesita agregar clases CSS a un informe Inline XBRL, debe asegurarse de que todas esas clases tengan el prefijo -ixv-, por ejemplo, -ixv-selected-fact.
Este documento también propone una clase CSS que se puede utilizar para proporcionar una pista al software de visualización de Inline XBRL (consulte la Sección 9). Esto utiliza un prefijo de -ixh-. El prefijo -ixh-también debe considerarse reservado y las clases CSS que comienzan con este prefijo no deben usarse en informes Inline XBRL ni en ninguna hoja de estilo adjunta, excepto como se describe en este documento o en los documentos publicados por XBRL International.
3. Eficiencia del HTML
El HTML de los informes XBRL en línea puede ser muy grande, en particular cuando se generan mediante un proceso de conversión de PDF a HTML, y esto puede provocar una carga y un rendimiento de representación lentos. Esto puede ser especialmente problemático para el software de visualización XBRL en línea, ya que dicho software normalmente requerirá que el informe se represente por completo antes de que el software pueda funcionar por completo.
La mejora del rendimiento de la representación en informes XBRL en línea se analiza con más detalle en la Nota del grupo de trabajo sobre rendimiento de la representación en XBRL en línea. Esta nota incluye una recomendación para utilizar la content-visibility: autopropiedad CSS, que puede mejorar sustancialmente el rendimiento de la representación de dichos documentos en algunos navegadores.
4. Selección de etiquetas HTML
La especificación Inline XBRL no impone ninguna regla sobre la elección de las etiquetas HTML utilizadas para lograr un resultado de diseño particular. Por ejemplo, no existe ningún requisito para marcar datos tabulares utilizando etiquetas <table>, <tr>y <td>, o para los encabezados que utilicen las etiquetas de encabezado HTML (<h1>, <h2>, <h3>, etc.). Estas características se pueden etiquetar utilizando etiquetas genéricas como <div>o <span>y aplicando el estilo apropiado, o mediante cualquier otro enfoque compatible con HTML.
El uso de etiquetas HTML más específicas puede mejorar la usabilidad y accesibilidad de los documentos HTML y, por lo tanto, de los informes Inline XBRL, pero no es requerido por la especificación Inline XBRL.
5. Etiquetas de bloque de texto
Inline XBRL proporciona un mecanismo para incluir el marcado HTML del documento de origen en un valor de hecho XBRL. Este mecanismo se habilita estableciendo el valor del escape atributo en un ix:nonNumeric elemento en true. Cuando está habilitado, cualquier etiqueta HTML que aparezca dentro de la etiqueta Inline XBRL se incluirá en el valor de hecho resultante. El valor de hecho resultante será un fragmento XHTML válido.
Si se establece como falso, las etiquetas HTML no se incluyen en la salida; solo se incluye contenido de texto. El valor de hecho resultante será texto sin formato.
Por ejemplo, considere una ix:nonNumeric etiqueta alrededor del siguiente contenido:

La interpretación de un valor de hecho está determinada por su tipo de datos. Los hechos que están destinados a contener XHTML normalmente utilizarán dtr-types:textBlockItemType. El valor de un hecho que utilice dtr-types:textBlockItemTypeDEBE ser XHTML válido, por lo que las etiquetas XBRL en línea para dichos hechos deben utilizar escape=»true»
Si escape=»false»se utiliza, los caracteres especiales que aparecen en el texto del hecho, como <,>y &no se escaparán mediante XML y, como resultado, el valor del hecho resultante puede no ser XHTML válido.
El uso de escape=»true»on hechos con tipos de datos que no están explícitamente designados como que tienen contenido XML o XHTML, como xbrli:stringItemType, dará lugar a un marcado inesperado en el valor del hecho resultante. Esto hará que las etiquetas XHTML se muestren directamente al usuario cuando vea dichos hechos en un software que los trate correctamente. De manera similar, si escape=»true»se utiliza on hechos con valores que contienen <o &, estos se escaparán de manera inapropiada a <y &cuando se muestren en un software compatible.
Por lo tanto, es importante que el valor del escapeatributo coincida con el tipo de datos del hecho:
- Los hechos con un tipo de datos de dtr-types:textBlockItemTypedeben utilizar escape=»true».
- Hechos con otros tipos de datos, como por ejemplo xbrli:stringItemTypedebería utilizar escape=»false».
5.1 Uso de escape=»false» en las etiquetas de bloques de texto
Si el contenido de texto de una etiqueta XBRL en línea no contiene caracteres que se deben escapar en XML (<y &), entonces es posible utilizarla escape=»false»en etiquetas de bloque de texto, ya que la cadena de texto sin formato resultante también es XHTML válido. Esto no suele recomendarse, ya que se perderá cualquier formato HTML dentro de la etiqueta.
5.2 Escapar al reserializar
En esta sección, las referencias a «valor de hecho» hacen referencia al valor semántico de un hecho en un informe XBRL. Si el informe se vuelve a serializar en otro formato, los valores de hecho deben tener el formato de escape adecuado para ese formato. Por ejemplo, cuando un informe se serializa en la sintaxis XML de XBRL v2.1 (xBRL-XML), los valores de hecho deben tener el formato de escape XML. Esto significa que un valor de hecho de:

Este escape no está relacionado con el comportamiento del escape atributo y es un artefacto del formato que se utiliza. Por ejemplo, si un hecho se serializara en xBRL-JSON, se sometería a un escape JSON (reemplazándolo \por\\, y «por\»).
6. Datos sobre los espacios en blanco en el texto
Cuando el contenido de un documento iXBRL se etiqueta mediante una ix:nonNumericetiqueta, se debe tener cuidado para garantizar que los valores de hechos extraídos del documento iXBRL preserven los espacios en blanco, de modo que se conserven los saltos entre palabras, párrafos y números.
En esta sección se describen algunos de los problemas más comunes.
6.1 Etiquetas HTML a nivel de bloque
Cuando una ix:nonNumericetiqueta utiliza el escape=»false»atributo predeterminado, el valor de hecho resultante es la concatenación de todos los nodos de texto que son descendientes de la etiqueta y de cualquier ix:continuationelemento al que se haga referencia. Si no se tiene cuidado en la construcción del HTML, el valor extraído puede no contener espacios en blanco en todos los lugares donde hay espacios visibles en el informe generado.
Un lugar donde esto puede ocurrir es si el texto está dividido en etiquetas de nivel de bloque HTML, como <p>o <div>:

Esto se presentará en dos párrafos separados:
Esta es la primera parte de la descripción.
Esta es la segunda parte de la descripción.
pero el valor del hecho extraído no incluirá ningún espacio entre las dos oraciones:
Esta es la primera parte de la descripción. Esta es la segunda parte de la descripción.
Incluir espacios en blanco entre el cierre </p>y la siguiente apertura <p>garantizará que se conserve el salto entre las oraciones y no afectará la representación del documento original:

Valor del hecho extraído:
Esta es la primera parte de la descripción. Esta es la segunda parte de la descripción.
Tenga en cuenta que este problema también se aplica a otros modos de visualización de CSS, como list-itemy table-row, y también a la <br>etiqueta.
6.2 ix:continuación
Una situación similar puede ocurrir cuando se utiliza ix:continuation. Esto puede afectar a las etiquetas que utilizan escape=»true»o escape=»false».
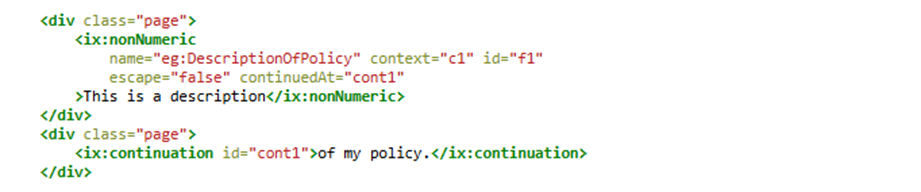
Esta disposición puede darse cuando una oración se divide en un salto de página o de columna. La vista renderizada mostrará la oración dividida en dos páginas o columnas:
Esta es una descripción
de mi política.
pero el valor del hecho extraído será:
Esta es una descripción de mi política.
Esta situación se puede evitar introduciendo espacio adicional dentro de los ix:continuationelementos.
6.3 Uso de estilos CSS para crear espacios
También es posible introducir espacios en la salida renderizada mediante estilos CSS. Por ejemplo:

Esto se visualizará así:
Mi política
pero el valor del hecho extraído (usando escape=»false») será:
Mi política
El comportamiento durante el uso escape=»true»dependerá del software de visualización y también puede depender de si el estilo se aplica mediante un estilo en línea o una clase CSS.
Cabe señalar que este uso de estilos para simular saltos de palabras también interferirá con las funciones estándar de los navegadores web, como copiar y pegar, y la búsqueda de texto, que tratarán el texto como si no hubiera espacios entre las palabras. De manera similar, cuando los documentos se publican en la web, es probable que esto afecte la indexación correcta por parte de los motores de búsqueda.
No se recomienda utilizar estilos para simular saltos de línea. En su lugar, el informe debe incluir espacios en blanco en el HTML y, si es necesario, ajustar el ancho del espacio representado utilizando otros medios.
6.4 Normalización de espacios en blanco (escape=»false»)
Al representar HTML, los navegadores aplican la normalización de espacios en blanco a la mayoría de los espacios en blanco. Esto significa que los espacios en blanco y otros caracteres de espacio en blanco, como tabulaciones y saltos de línea, se representan como un solo espacio. Por ejemplo, los dos ejemplos siguientes se representarán de la misma manera:

Al extraer valores de hechos XBRL de una ix:nonNumericetiqueta con escape=»false», se conservan todos los espacios en blanco del documento original. Esto significa que el valor de hecho resultante para los dos ejemplos anteriores será diferente.
La especificación XBRL en línea no prescribe cómo deben presentarse dichos valores de hechos a un usuario final y no define si se debe aplicar la normalización de espacios en blanco.
7. Compatibilidad con HTML
El XBRL en línea requiere que los documentos sean XHTML válido, la sintaxis basada en XML para HTML. Aunque son similares, los navegadores tratan XHTML y HTML de forma diferente. El que un documento se trate como XHTML o HTML depende de una serie de factores, no todos los cuales están bajo el control del autor del documento. Por ejemplo, cuando un informe se coloca en un sitio web, el modo puede estar controlado por el tipo de contenido HTTP con el que se sirve, que dependerá de la configuración del servidor.
De manera similar, cuando se extraen hechos de bloques de texto de un informe iXBRL, es posible que las herramientas que consumen el hecho resultante no siempre lo traten como XHTML en lugar de HTML.
Por este motivo, se recomienda que los informes iXBRL se construyan de forma que se representen correctamente tanto en modo XHTML como HTML. Hay tres cuestiones que se deben tener en cuenta al hacer esto:
- Uso de etiquetas de cierre automático;
- Reglas de escape; y
- Modo de renderizado del navegador.
Estos se analizan con más detalle a continuación.
7.1 Uso de etiquetas de cierre automático
En XML, una etiqueta vacía puede ser «autocerrada» <br />y <br></br>son completamente equivalentes en XML y, por lo tanto, en XHTML.
En HTML, las etiquetas que solo pueden estar vacías, como br, no pueden tener una etiqueta de cierre, y un analizador HTML tratará una </br>etiqueta de cierre como si fuera otra <br>etiqueta. Esto significa que <br></br>se tratarán como dos <br>etiquetas, lo que produce una diferencia en la representación entre HTML y XHTML. Afortunadamente, las etiquetas autocerradas ( <br />) también se tratan como una sola etiqueta, por lo que los elementos autocerrados que solo pueden estar vacíos producen los mismos resultados en HTML y XHTML.
Por el contrario, las etiquetas de cierre automático que se espera que tengan contenido también darán lugar a diferencias entre HTML y XHTML. Por ejemplo, en XHTML, una span etiqueta vacía se puede representar como <span />, pero en HTML esto se interpretará como una etiqueta de apertura (una etiqueta de cierre se inferirá en algún punto más adelante en el documento). Esto produce una estructura DOM diferente, con el resultado de que el estilo CSS se puede aplicar de forma diferente.
Para garantizar la coherencia entre HTML y XHTML, las etiquetas que deben estar vacías deben utilizar la sintaxis de etiqueta de cierre automático, mientras que las etiquetas vacías a las que se les permite contener contenido deben utilizar la notación expandida.
7.2 Reglas de escape
XHTML debe ser XML bien formado, lo que significa que los caracteres especiales XML ( <y &) siempre deben estar ocultos. >Normalmente no es necesario ocultar el carácter en XML, pero con frecuencia se hace para mantener la coherencia con <.
HTML sigue reglas de escape similares, pero aplica reglas diferentes dentro de distintos elementos, especialmente los elementos <style>y <script>.
No se espera que el contenido con una <style>etiqueta tenga formato de escape XML en HTML, y se debe seguir una regla de estilo CSS como:

Por lo tanto, >no se deben escapar dentro de <style>las etiquetas.
<y &no forman parte de la sintaxis CSS, pero pueden aparecer en comentarios CSS y cadenas CSS. En este último caso, se pueden representar mediante las secuencias de escape Unicode \00003Cy \000026respectivamente.
Un problema similar ocurre con el contenido de <script>la etiqueta, donde los caracteres especiales XML deben ser escapados en XHTML, pero no deben serlo en HTML. Como el contenido de script no suele estar permitido en los entornos de generación de informes iXBRL, no se analizan más los métodos para abordar este problema.
En ambos casos, estos problemas de escape se pueden evitar por completo colocando el estilo o el contenido del script en un archivo separado.
7.3 Modo de renderizado
Además de los problemas sintácticos mencionados anteriormente, los navegadores, de forma predeterminada, utilizan distintos modos de representación para los documentos XHTML y HTML. Los documentos XHTML utilizan el «modo estándar», mientras que los documentos HTML utilizan el «modo peculiar».
En general, estos dos modos producen los mismos resultados, pero ciertas construcciones HTML y CSS se tratan de forma diferente. Una discusión completa de las diferencias queda fuera del alcance de este documento, pero en muchos casos, estas diferencias se pueden resolver utilizando construcciones CSS más explícitas.
8. Enlace CSS de hechos ocultos
El uso de reglas de transformación de Inline XBRL para convertir los valores legibles por humanos en un informe HTML en los formatos requeridos para los hechos XBRL proporciona cierta garantía de coherencia entre la información legible por humanos y la información legible por computadora.
En algunos casos, puede que no exista una regla de transformación adecuada, en cuyo caso, la única forma de etiquetar el hecho es incluirlo en la ix:hiddensección del informe XBRL en línea. Un caso de uso común para esto son los hechos que utilizan enumeraciones extensibles, donde el valor de URI o QName requerido para el valor del hecho XBRL no es adecuado para un informe legible para humanos.
La colocación de datos ix:hiddenrompe el vínculo entre el valor legible por humanos y el valor del dato XBRL. Algunos sistemas de archivos han adoptado una propiedad CSS personalizada que se puede aplicar a un elemento HTML para crear un vínculo entre un elemento HTML visible y un dato en la ix:hiddensección. Las siguientes propiedades CSS personalizadas están en uso activo:
- -sec-ix-hidden
- -esef-ix-hidden
En ambos casos, el valor de la propiedad CSS es el ID de un hecho en la ix:hiddensección del informe. El elemento HTML al que se aplica la propiedad debe contener el contenido legible por humanos que corresponde al valor del hecho con ese ID.
Esto permite que el software de visualización Inline XBRL muestre el valor del hecho XBRL asociado con el valor presentado, lo que hace más fácil para los revisores garantizar la coherencia entre ambos.
Este mecanismo proporciona un vínculo mucho más débil que el uso de reglas de transformación, ya que no ofrece garantías de que exista correspondencia entre el valor legible por humanos y el valor de hecho de XBRL. El grupo de trabajo está desarrollando nuevos mecanismos que puedan gestionar mejor los casos de uso en los que ix:hiddenactualmente se requieren hechos, pero también reconoce que los vínculos creados mediante estas propiedades CSS personalizadas son mejores que no tener ningún vínculo y que estos mecanismos proporcionan una solución pragmática a corto plazo.
Para evitar la proliferación de propiedades similares, se recomienda que los sistemas de archivo que busquen adoptar un enfoque similar utilicen el siguiente nombre de propiedad CSS personalizado:
- -ix-hidden
La propiedad debe aplicarse a un elemento HTML visible que contenga contenido que corresponda al valor de un hecho XBRL oculto, y el valor de la propiedad debe ser el ID de ese hecho XBRL oculto.
Se debe tener en cuenta que colocar elementos Inline XBRL dentro del HTML visible y usar transformaciones (cuando sea necesario) sigue siendo la forma preferida de etiquetar informes Inline XBRL, y el ix:hiddenelemento, incluso con el vínculo proporcionado por esta propiedad CSS, solo debe usarse cuando sea absolutamente necesario.
9. Contenedor de sugerencias para resaltar
El software que muestra informes iXBRL generalmente resaltará hechos dentro del informe para diferentes propósitos. Determinar exactamente qué región del informe resaltar no es trivial, ya que cualquier enfoque que se adopte debe lidiar con la amplia variedad de estructuras HTML diferentes que se ven en los informes iXBRL del mundo real.
El uso generalizado de elementos de posición absoluta, impulsado en gran medida por el uso de software de conversión de PDF a HTML, agrega complejidad adicional a esto, e incluso cuando dicho HTML se maneja correctamente, el resultado final puede ser algo desordenado.
Por ejemplo, cuando se construyen párrafos completos de texto utilizando <p></p> etiquetas y luego se etiquetan, se puede aplicar un contorno o color de fondo a los párrafos en su totalidad.

El software de conversión de PDF a HTML suele utilizar un elemento independiente con una posición absoluta para cada línea dentro del párrafo. Si un lector puede hacer esto, es probable que agregue un borde o un color de fondo a cada línea individualmente, como se muestra a continuación:

Si hay un solo elemento envolvente para el contenido, de manera predeterminada tendrá ancho y alto cero, por lo que resaltarlo no tendrá el efecto deseado.
Este documento propone un mecanismo que puede ser utilizado por el software de creación para proporcionar una pista que permitirá al software de visualización resaltar más claramente dicho contenido.
Cuando el antecesor HTML más cercano de un elemento ix:footnote, ix:nonNumeric, ix:nonFraction, ix:fraction, o ix:nonNumerices un elemento HTML con una clase de -ixh-highlight-region, el elemento HTML debe tener una posición y dimensiones que correspondan al contenido dentro de la etiqueta. El software de visualización puede optar por aplicar el resaltado a ese elemento, en lugar de intentar determinar la extensión del contenido representado por las etiquetas iXBRL.
Esto producirá una apariencia similar a la Figura 1.
Cuando varios elementos iXBRL etiquetan el mismo contenido (etiquetas anidadas), pueden compartir la misma sugerencia de resaltado colocándola alrededor del elemento iXBRL más externo.
Publicado originalmente: https://www.xbrl.org/news/designing-html-for-inline-xbrl-updated-guidance/