XBRL – las partes buenas
Hay mucho que me gusta de XBRL.
Después de siglos de papel y décadas de formatos digitales opacos y patentados, XBRL fue la tecnología innovadora que permitió intercambiar informes comerciales de forma rápida, amplia y confiable.
XBRL es un estándar maduro que ha demostrado su eficacia en el mundo real. Todas las empresas que cotizan en bolsa en los EE. UU. Y los principales bancos y compañías de seguros de Europa presentan sus registros ante sus reguladores en XBRL. Solo en el Reino Unido, 4 millones de empresas han presentado más de 20 millones de solicitudes XBRL.
XBRL fue diseñado desde el principio para ser un estándar global, con una estructura modular y extensible que permite que múltiples jurisdicciones aumenten un conjunto común de definiciones base con nuevas etiquetas y conceptos de informes específicos de cada país. Ha sido adoptado por docenas de países en todos los continentes excepto en la Antártida.
XBRL tiene un sistema de tipos enriquecido, que cubre no solo datos numéricos, sino también texto, fechas, URI e incluso formatos definidos por el usuario, todo lo necesario para capturar la información legible por máquina en un informe comercial. XBRL también proporciona un medio claro para capturar unidades de medida, que a menudo quedan implícitas en otras representaciones.
XBRL incluye un mecanismo estándar para expresar reglas complejas de validación dimensional y características de representación enriquecidas que garantizan que el remitente y el receptor puedan compartir una vista común de un informe comercial, al tiempo que conservan la capacidad de dividirlo y dividirlo para su análisis.
Las especificaciones de XBRL están respaldadas por amplios conjuntos de conformidad y un proceso de certificación de XBRL International que ofrece altos niveles de interoperabilidad en una amplia gama de software estándar.
Aunque los beneficios comerciales de XBRL son claros, se puede perdonar a los tecnólogos que profundizan en la sintaxis y las especificaciones de XBRL por retroceder horrorizados.
Buenas intenciones y pifias
Todos los estándares no triviales pueden ser abrumadores cuando los aborda a nivel de sintaxis, con solo las especificaciones para guiarlo en lugar de API e interfaces gráficas. Con XBRL, esto es especialmente cierto.
XBRL se definió en 2003, en términos de tres tecnologías clave que parecían razonables en ese momento: XML, XML Schema y XLink.
XML fue un refinamiento valioso de SGML y es una elección natural para documentos semiestructurados de “contenido mixto” como HTML e Inline XBRL. En 2003, XML seguía siendo una opción popular para datos estructurados, pero JSON proporciona un medio mucho más simple de transmitir modelos de objetos de una computadora a otra, y esto ahora se reconoce universalmente. El mundo ha avanzado.
XML Schema es un lenguaje extremadamente poderoso para restringir la forma de XML, y sigue siendo la tecnología más utilizada para este propósito, pero tiene mucha complejidad, no toda la cual es necesaria para XBRL.
Mientras tanto, XLink no ha tenido una adopción generalizada fuera de XBRL. Fue en un sentido y la web semántica fue en otro.
Para empeorar las cosas, toda la rica funcionalidad que XBRL obtuvo posteriormente (para dimensiones definidas por taxonomía, reglas de validación y renderizado) se definió en términos de la sintaxis original, en lugar de un modelo lógico desacoplado de ella.
Nada de esto ha impedido que XBRL se convierta en el estándar líder para los informes comerciales, pero ha complicado la vida de los desarrolladores y ha ralentizado la adopción. De hecho, algunas organizaciones conocedoras de la tecnología han encontrado los detalles de sintaxis lo suficientemente desagradables como para quedarse con formatos propietarios, o idear otros nuevos, renunciando a los beneficios del estándar XBRL.
El modelo de información abierta
Durante los últimos años, un grupo de nosotros hemos estado trabajando para mejorar los fundamentos técnicos de XBRL, preparando el escenario para una adopción más fácil y generalizada del estándar.
El modelo de información abierta define formalmente el modelo lógico independiente de la sintaxis que siempre ha estado ahí detrás de escena. Precisa qué partes de la sintaxis XML original de XBRL son semánticamente significativas y cuáles son irrelevantes.
En el camino, hemos aprovechado la oportunidad para simplificar el estándar eliminando funciones que agregan mucha complejidad sin beneficios compensatorios. En particular, OIM prohíbe el uso de estructuras jerárquicas anidadas arbitrariamente, que no encajan cómodamente con el modelo dimensional de XBRL.
También hemos definido dos nuevas representaciones del modelo, cada una de las cuales proporciona diferentes beneficios sobre la sintaxis XML original.
xBRL-JSON
JSON se puede serializar y deserializar trivialmente en todos los lenguajes de programación principales, lo que lo convierte en el formato de elección para las API web.
xBRL-JSON está diseñado para este entorno, como la expresión más simple y clara del modelo de información abierta.
Proporciona una representación plana y desnormalizada para cada punto de datos, con toda la información dimensional inmediatamente accesible.
Mientras que la sintaxis XML tiene una variedad de estructuras para representar información similar, xBRL-JSON representa todas las dimensiones de manera consistente, ya sea que estén integradas en el estándar o definidas por los usuarios en una taxonomía.
Los beneficios de la nueva representación JSON se vuelven obvios cuando ve un ejemplo.
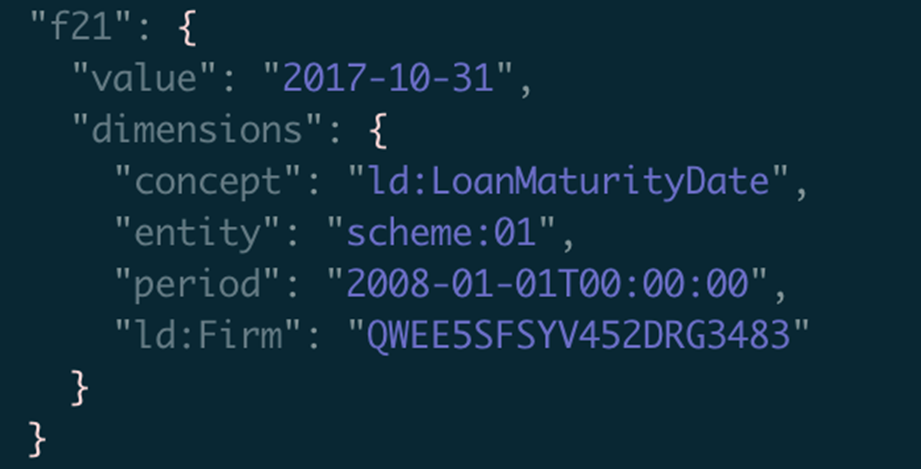
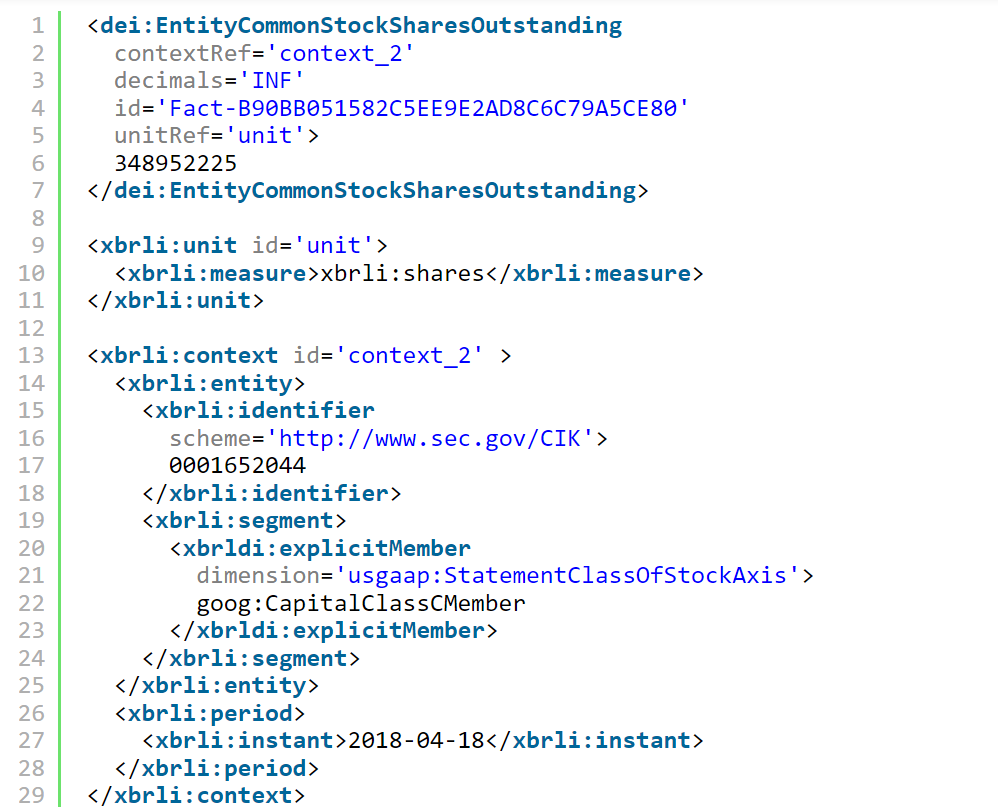
Aquí hay una representación xBRL-XML de un solo punto de datos:
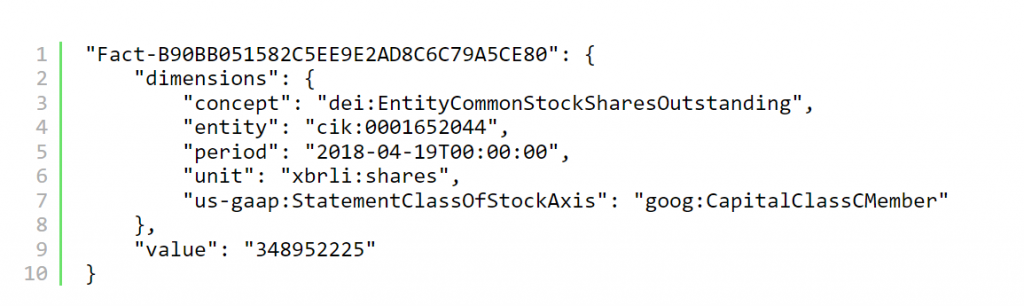
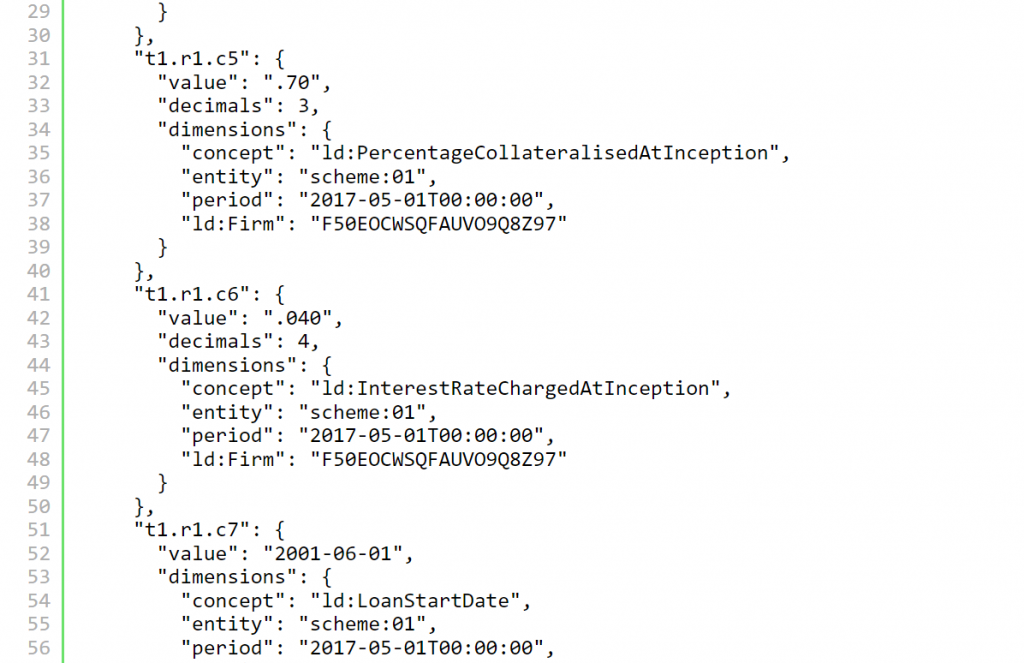
Aquí está la representación xBRL-JSON de ese mismo punto de datos:
xBRL-CSV
Para conjuntos de datos grandes, e incluso algunas aplicaciones de ciencia de datos más pequeñas, es el venerable archivo CSV el formato de elección. CSV por sí solo omite una gran cantidad de metadatos importantes, que XBRL aporta.
Los reguladores están cada vez más interesados en recopilar datos detallados a «nivel de transacción», y CSV es ideal para esto. Nuestras pruebas iniciales han mostrado reducciones significativas en el tamaño del archivo en comparación con las representaciones xBRL-JSON y xBRL-XML.
La representación CSV de OIM utiliza un archivo JSON de soporte para vincular el modelo de taxonomía XBRL enriquecido con las filas y columnas en una colección de archivos CSV. Al colocar los hechos con el mismo desglose dimensional en el mismo archivo CSV, evitamos muchas declaraciones repetidas y colocamos los hechos con el mismo contexto dimensional convenientemente juntos en la misma fila:

Aquí está la representación JSON correspondiente para la primera fila:
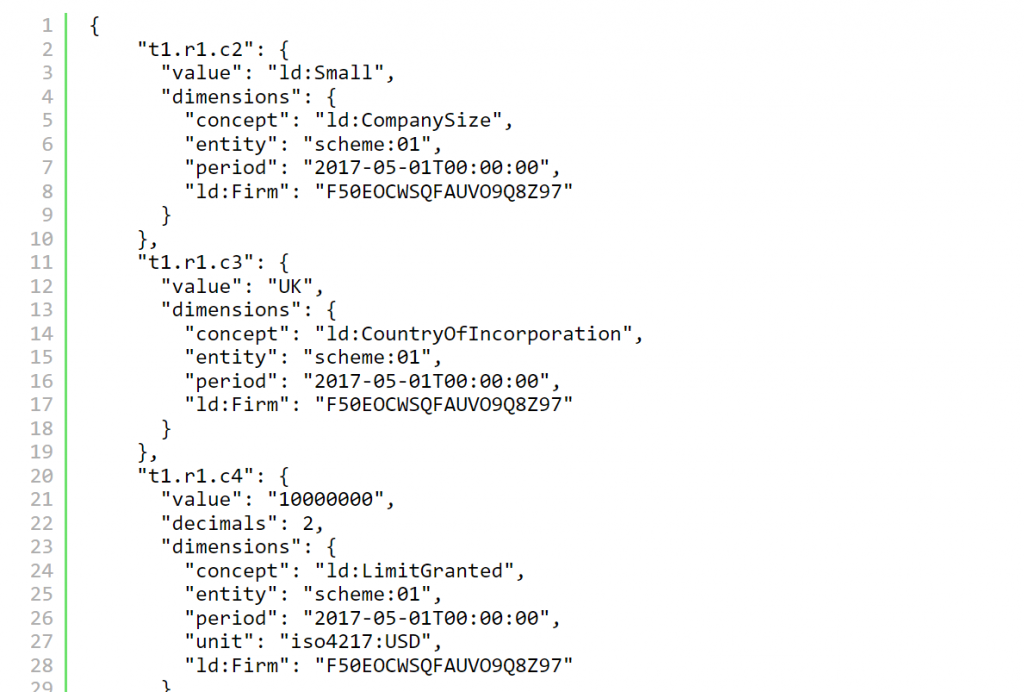
La compacidad de la representación CSV se logra mediante:
- compartir información a través de hechos en una fila
- p. ej. ld:Firm=F50EOCWSQFAUVO9Q8Z97para la fila 1
- compartir información a través de hechos en una columna
- p. ej. concept=ld:LimitGranted; decimals=2; unit=iso4217:USDpara la columna 4
- compartir información común a todo el archivo
- p.ej period=2017-05-01T00:00:00; entity=scheme:01

El formato CSV aún está en desarrollo, pero se espera que el archivo JSON de metadatos siga el diseño de la especificación de metadatos tabulares del W3C . Se verá ampliamente así:
El camino al estado de Recomendación
Los esfuerzos de estandarización generalmente toman más tiempo de lo esperado, y OIM no ha sido una excepción, pero ahora está en la recta final.
Esperamos que el modelo central y la representación JSON alcancen el estado final de «Recomendación» a mediados de 2019, y la representación CSV le seguirá a fines de 2019.